

ChatGPTを仕事で使っている方なら、この数ヶ月で「またモデルが増えた」と感じた経験があるんじゃないでしょうか。GPT-5、GPT-5.1、GPT-5.2、GPT-5.3-Codex、GPT-5.4。そしてつい49日前にGPT-5.4が出たばかりなのに、また新しいモデルが降ってきました。2026年4月23日、OpenAIが正式発表したのがGPT-5.5です。
今回のリリースは、単なる世代更新というより、AIの役割を「ツール」から「同僚」寄りに動かそうとする意図がはっきり出ていると思います。OpenAIはGPT-5.5を「実務とエージェントのための新しい知能クラス」と位置付けました。社内コードネームは「Spud(じゃがいも)」と報じられていて、派手さとは裏腹に、日常の泥くさい仕事をじっくり片付けてくれるイメージを狙ったのかもしれません。
この記事では、一次情報ベースでGPT-5.5の概要と料金を整理しつつ、GPT-5.4からの進化点、SNSでの反応、そして仕事で使うときの注意点までをまとめてお届けしたいと思います。自分の業務に引き付けて「どこから試すか」を決める材料にしてもらえたら嬉しいです。
GPT-5.5とは何か|まず「使える人」と「場所」の話
GPT-5.5は、ChatGPTとCodexの両方に即日展開されました。いつものようにクラウド経由で静かに置き換わっているタイプのリリースなので、自分で切り替えなければ気づかないまま使っている、という人もいるかもしれません。
使える範囲はプランで明確に分かれます。ChatGPTではPlus(月額20ドル)、Pro(月額200ドル)、Business、Enterpriseのユーザーに順次ロールアウトされている状況です。ここで一つポイントになるのが、無料プランは対象外という点ではないでしょうか。GPT-5系の前モデルは無料枠にも段階的に降りてきましたが、少なくともGPT-5.5の本体は当面有料契約者の領域にとどまる見込みです。
さらに上位モデルとしてGPT-5.5 Proが別立てで用意されていて、こちらはPro/Business/Enterpriseのみに提供されます。同じ名前の「Pro」でも、プランとしてのProと、モデルとしてのPro(GPT-5.5 Pro)は別レイヤーなので混乱しやすいかもしれません。
API料金とコンテキストウィンドウ
開発者向けのAPI料金も整理しておきます。GPT-5.5は入力が100万トークンあたり5ドル、出力が30ドル。上位のGPT-5.5 Proは入力30ドル、出力180ドルです。GPT-5.4が入力2.50ドル/出力15ドルだったことを踏まえると、おおむね倍増と受け取ってよいでしょう。
コンテキストウィンドウは100万トークン。大きめのコードベースや社内ドキュメント群を丸ごと放り込んで、そこに対してエージェントが仕事をする、という使い方を前提に設計されている印象です。学習・推論基盤にはNVIDIAのGB200とGB300 NVL72が使われているとのことで、裏側のインフラも相応の規模で組まれているのが伝わってきます。
GPT-5.4から何が進化したのか|4つのポイント
ここが一番気になるところじゃないかと思います。「また賢くなりました」で終わらせず、具体的に何が動いたのかを4つに整理してみます。
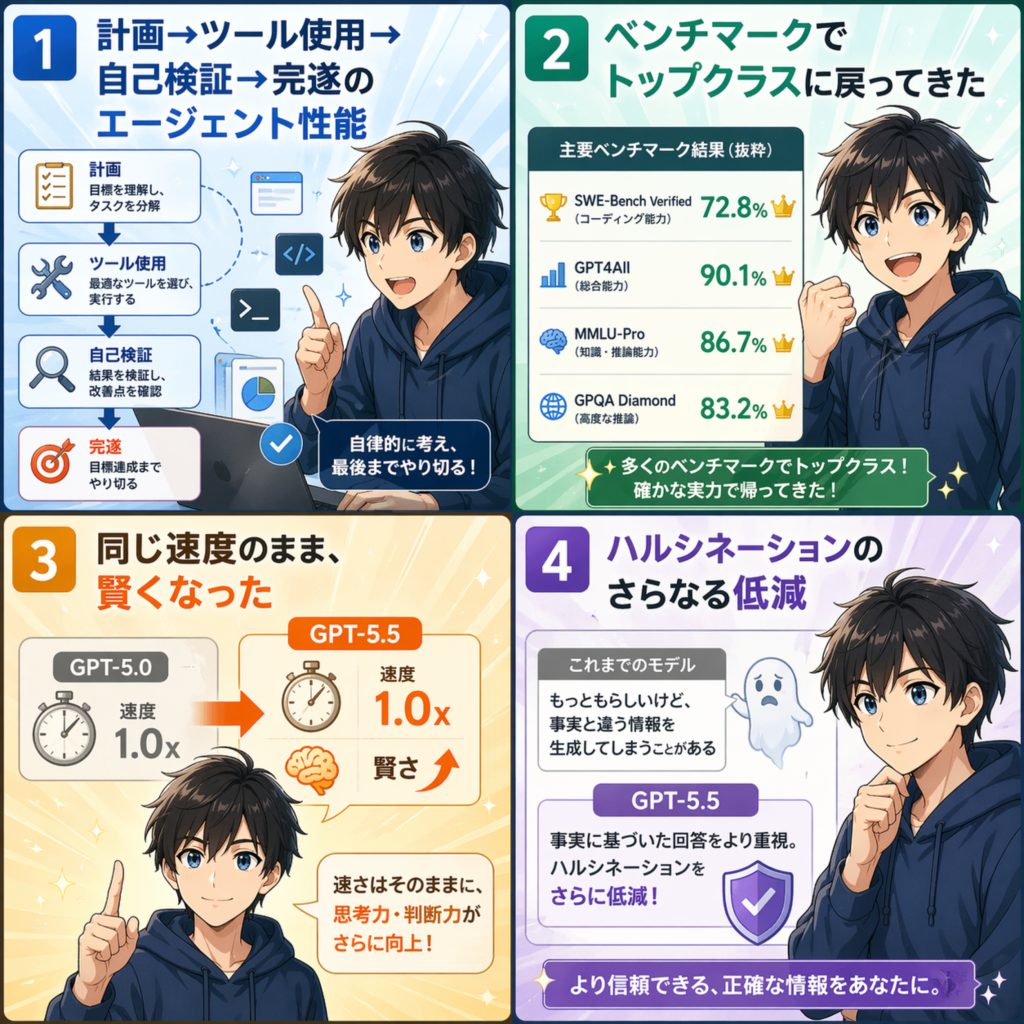
1. 計画→ツール使用→自己検証→完遂のエージェント性能
OpenAIがGPT-5.5で最も強調しているのが、この「タスクを最後までやりきる力」です。複雑な目標を理解して、必要なツールを自分で選び、途中で結果をチェックして、完了まで運ぶ。人間が段階ごとにプロンプトを積む必要が減ったという説明の仕方をされています。
得意領域としては、エージェント的コーディング、コンピュータ使用、データ分析、ドキュメントやスプレッドシートの作成、オンラインリサーチ、初期段階の科学研究といった具体名がOpenAI側から挙がりました。ここでいう「エージェント的コーディング」は、GitHubのIssueを読んで、該当コードを探し、修正して、テストを流し直して、プルリクまで作る、といった一連の流れが想定されているはずです。
2. ベンチマークでトップクラスに戻ってきた
スコアの話もしておきます。Terminal-Bench 2.0という、CLI上で計画・反復・ツール連携を要する複合ワークフローを測るベンチマークで、GPT-5.5は82.7パーセントを記録しました。Anthropic Claude Opus 4.7の69.4パーセントを明確に上回っています。
ほかに押さえておきたいのは次の数字でしょうか。実世界のGitHub Issue解決を評価するSWE-Bench Proで58.6パーセント。44職種の知的労働タスクを評価するGDPvalで84.9パーセント。実PC環境をモデル単体で操作するOSWorld-Verifiedで78.7パーセント。複雑なカスタマーサポート業務を扱うTau2-bench Telecomでは、プロンプトチューニングなしで98.0パーセントという数字が出ています。
ベンチマークはあくまで「仮の現場」なので、そのまま実務に置き換えられるわけではありません。それでも、エージェント系の評価軸で前世代と大きな差がついたこと自体は、方向性としての進化を示していると思います。
3. 同じ速度のまま、賢くなった
GPT-5.5は、実運用でのトークンあたりレイテンシがGPT-5.4と同等を維持したまま、知能レベルを引き上げたと説明されています。同じ評価タスクをより少ないトークンでこなせるようになっていて、推論の効率が改善したとのこと。
使う側にとって嬉しいのは、「reasoning effort」のレベルでコストと性能を調整できる点かもしれません。軽いタスクは浅い推論で安く速く、重いタスクは深い推論でしっかり時間をかけて、と使い分ける前提が整備されています。ここは実際にAPIで組んでいる人ほど効いてくる設計じゃないでしょうか。
4. ハルシネーションのさらなる低減
事実誤認の抑制は、GPT-5系を通して継続して改善されてきたポイントです。参考値として、GPT-5.2のハルシネーション率は6.2パーセント(GPT-5.1の8.9パーセントから低下)と報告されており、GPT-5.5ではさらに改善したと報じられています。
金融や医療といった規制の強い領域で「事実性をどこまで担保できるか」に重心を置いた調整が行われた、という報道もありました。ここは実際の業務で効いてくるかどうか、ドメインごとに自分の目で確かめる必要があるでしょう。
SNSやコミュニティでの反応|AIが「ツール」から「同僚」に近づいた
ここからはリサーチ単体では拾いきれなかった、SNS側の温度感をまとめておきたいと思います。
まずポジティブな声。圧倒的に多いのが、タスク完遂力への絶賛です。「複雑な目標を理解し、ツールを使い、自らチェックして最後までやりきる」「これまでで初めて本当に仕事を終わらせるモデル」「messyなマルチタスクを任せられる」といった表現が目立ちました。従来の「指示を一つずつ管理する必要」が減って、自律的な実務利用が本格化した、という捉え方が中心になっているように見えます。
ベンチマーク面では、Terminal-Bench、Expert-SWE、GDPval、OSWorld、CyberGymなどで高スコアを記録し、Artificial Analysis Intelligence Indexで明確な1位に返り咲いたとの報告も拡散されていました。NVIDIA社員1万人超へのCodex全社展開が話題になったのも、このタイミングだったようです。
効率面は評価が割れました。「GPT-5.4並みのレイテンシとトークン数で大幅に賢くなった」「reasoning effortでコストと性能を調整できるのが嬉しい」という好意的な声が多い一方で、「入力5ドル・出力30ドルはやっぱり高い」という指摘もありました。ただ、トークン効率が上がった分で相殺される、という見方が落ち着きどころになりつつあるように感じます。
冷静な反応・ネガティブな声としては、次のようなものがありました。ハルシネーションはゼロではない、という指摘は相変わらず。writingが無個性という感想も見かけます。価格上昇への懸念もちらほら。あとは「49日ぶりの更新」というリリースペースへの驚きも多く、開発者側の検証サイクルが追いつかないという率直な声も上がっていました。
全体のムードとしては、興奮と期待が強めというところでしょうか。Sam AltmanやNVIDIAのJensen Huang関連の投稿が拡散され、「AIがツールから同僚へ」「経済加速の鍵」といった楽観的な論調も広がっています。開発者とビジネスユーザーを中心に即試用の報告が増えていくはずです。
GPT-5.5を仕事で使うときに押さえておきたい注意点
数字や反応を並べてきましたが、ここでは実務に引き付けた「落とし穴」のほうを整理しておきます。以下は特に頭に入れておきたいポイントです。
- API出力コストがGPT-5.4から倍増。エージェント系の処理は試行錯誤で出力トークンが膨らみやすく、気づくと月次費用が想定を大きく超えている、ということが起きやすい
- 無料ユーザーはGPT-5.5の恩恵を受けられない。前世代を使い続けることになるので、少なくともPlus(月額20ドル)以上が前提になる
- リリース間隔が短くなっていて、社内の評価・検証・ガイドライン更新が追いつかない可能性がある。導入判断を止めるのではなく、評価のサイクル自体を軽くする設計が必要になるでしょう
- 自律性が高いぶん、権限設計やログ、途中キャンセル・取り消しの手段が甘いと、被害も自律的に広がる。ガードレールを先に整えておくのが安全
- ベンチマークで強くても、実プロジェクトの独自ライブラリや大規模コードベースではスコアほど動かないケースがある。本番投入前にドメイン固有の小さな評価を一度挟んでおきたい
- 競合(Claude Opus 4.7、Gemini 3.1 Proなど)との差は数週間で逆転しうる距離感。特定モデルへの深いロックインは避け、差し替え可能なアーキテクチャで組むのが長期的には楽なはずです
まとめ|まず何から試すか
GPT-5.5の核は、一言でいえば「一発で仕事が終わる確率を上げる」ことじゃないかと思います。これまで指示を細かく渡して、途中経過を確認して、出力をつなぎ直してきた工程が、そのまま短くなる可能性があります。うまくハマれば、人間の側は「何を任せて、結果をどう検収するか」に時間を使えるようになるはずです。
だからといって、一気に全工程を任せる必要はありません。最初の一歩として提案したいのは、普段ChatGPTに依頼している「ちょっと面倒な複数工程のタスク」を1つだけ選ぶことです。リサーチして、要点を整理して、表にして、メール文面まで起こす、みたいな流れが典型だと思います。
そのタスクを、まずGPT-5.4で走らせる。次に同じプロンプトでGPT-5.5にも走らせる。どこがどう違ったか、短く比較メモを取る。これだけで、短期のコスト増と長期の時間削減を、抽象論ではなく自分の業務の数字として見ることができます。
モデルは今後もこの速度で更新され続けるでしょう。追いかけ続けるより、「自分の仕事の中で、AIに任せる領域の輪郭を少しずつ動かす」ほうが、長い目で見て効いてくる気がします。GPT-5.5はその輪郭を動かしやすくしてくれるモデルとして、一度は触っておく価値があると言ってよさそうです。








{kind=link}
コメント